
I+D+i
Anticiparnos, experimentar, explorar, provocar el cambio, centrarnos en las personas y estar a la última. Queremos que el bosque y sector forestal se beneficien de nuevas formas de hacer y de pensar, con ciencia y tecnologías vanguardistas.
I+D+i
Anticiparnos, experimentar, explorar, provocar el cambio, centrarnos en las personas y estar a la última. Queremos que el bosque y sector forestal se beneficien de nuevas formas de hacer y de pensar, con ciencia y tecnologías vanguardistas.








Valores
Practicamos los valores del cooperativismo, una fórmula democrática y solidaria de entender la sociedad, el empleo y la participación de las personas en la economía, en igualdad y equidad.
Valores
Practicamos los valores del cooperativismo, una fórmula democrática y solidaria de entender la sociedad, el empleo y la participación de las personas en la economía, en igualdad y equidad.
Proyectos destacados












Blog

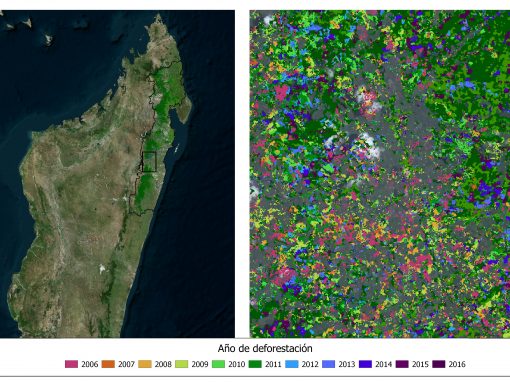
Resultados de SOILPROECT frente las lluvias provocadas por la borrasca Nelson
El paso de la borrasca Nelson ha dejado abundantes lluvias en buena parte de la Península ... leer más

Día Internacional de los Bosques 2024: innovación aplicada a la gestión forestal
Desde AGRESTA, con motivo del Día Internacional de los Bosques, os queremos hacer partícipes ... leer más
Formamos parte de…














Entidad subvencionada por:

En Agresta nos adherimos a los principios de la economía social y solidaria. Es por esta razón que anualmente realizamos un proceso de reflexión interna que culmina con un informe y un sello, garantía de transparencia, democracia y compromiso con la existencia de otra forma de realizar nuestras prácticas empresariales, compartiendo además un logro y un reto. Tratamos de poner en valor las prácticas éticas que realizamos y construir una sociedad que tenga más en cuenta a las personas, su entorno y el medioambiente. Quieres acceder al Balance Completo de Agresta pincha en este enlace.